A tournament bracket UI where you pick your favorite between two coding fonts and your choices are whittled down all the way to a final winner. A clever way to suss out your own taste and arrive at a choice.
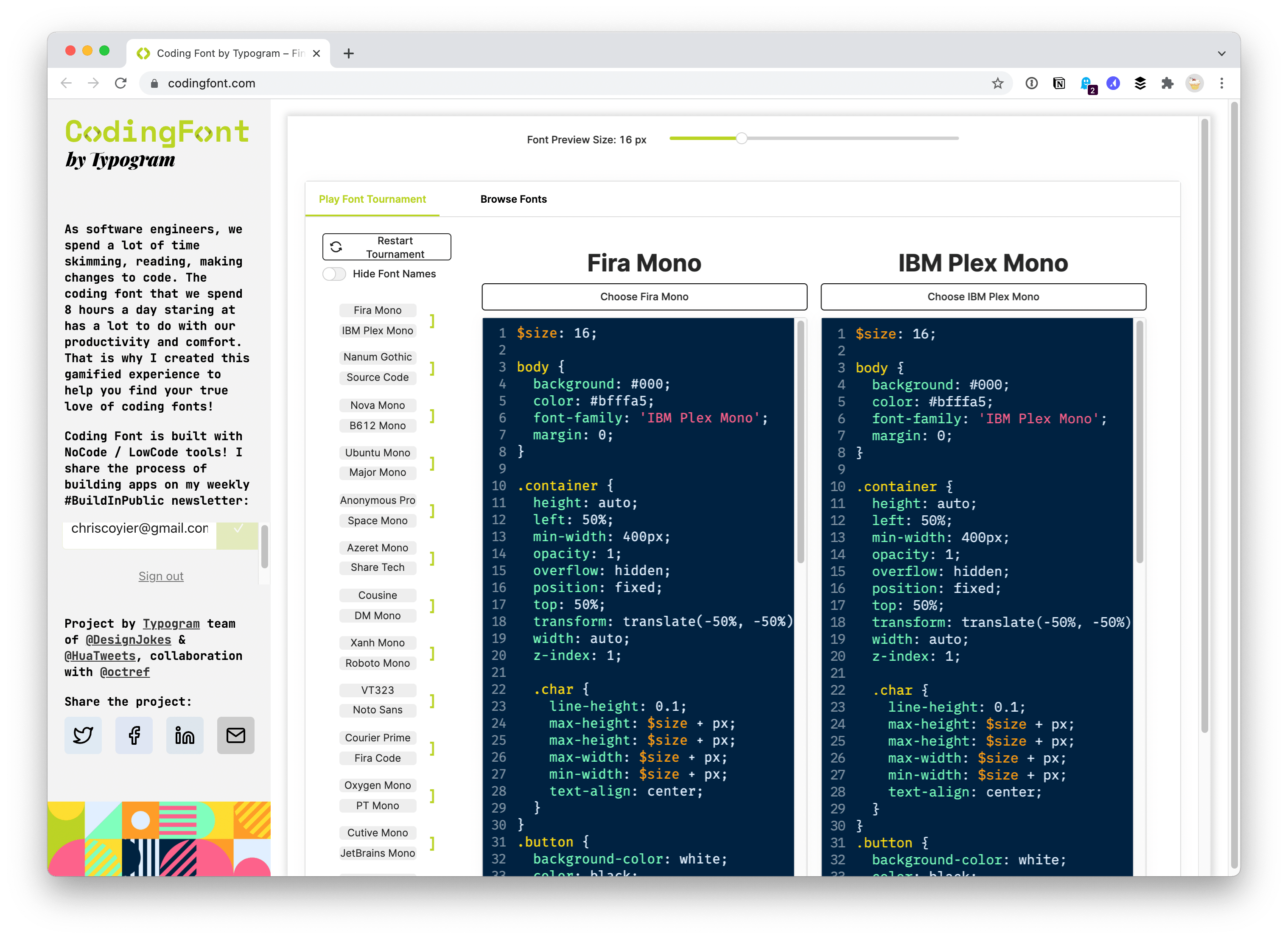
(P.S. We have our own little coding fonts website to showcase some high-quality favorites.)
Wenting Zhang documented in a newsletter that she built it the whole thing with Retool, meaning she had to write very little code directly, and instead used pre-built components. That’s kind of the point of Retool. It’s like a UI library with existing components for building stuff out quickly, but it goes the extra mile in connecting to your own data.
Five years ago, if I wanted to build this coding font game, I would have had to spend days or weeks hand-coding it in React or other frameworks. But since then, I have discovered no code and low code apps which are essentially libraries of pre-existing informational or functional things. They can be powered by a database or an API, and the interaction layer is standard, often with minimal customization needs.
The two bits of code shared in that post look… pretty complicated. So, in this case, it’s a “low code” thing where those bits of code really hone in on the core functionality and experience, but a lot of the rest of the more mundane and boilerplate code is avoided. Seems compelling to me. In the end, the whole “game” is an <iframe> pointing to the Retool widget thing.