Speeding up computations is a goal that everybody wants to achieve. What if you have a script that could run ten times faster than its current running time? In this article, we’ll look at Python multiprocessing and a library called multiprocessing. We’ll talk about what multiprocessing is, its advantages, and how to improve the running time of your Python programs by using parallel programming.
Okay, so let’s go!
An Introduction to Parallelism
Table of Contents
Before we dive into Python code, we have to talk about parallel computing, which is an important concept in computer science.
Usually, when you run a Python script, your code at some point becomes a process, and the process runs on a single core of your CPU. But modern computers have more than one core, so what if you could use more cores for your computations? It turns out that your computations will be faster.
Let’s take this as a general principle for now, but later on, in this article, we’ll see that this isn’t universally true.
Without getting into too many details, the idea behind parallelism is to write your code in such a way that it can use multiple cores of the CPU.
To make things easier, let’s look at an example.
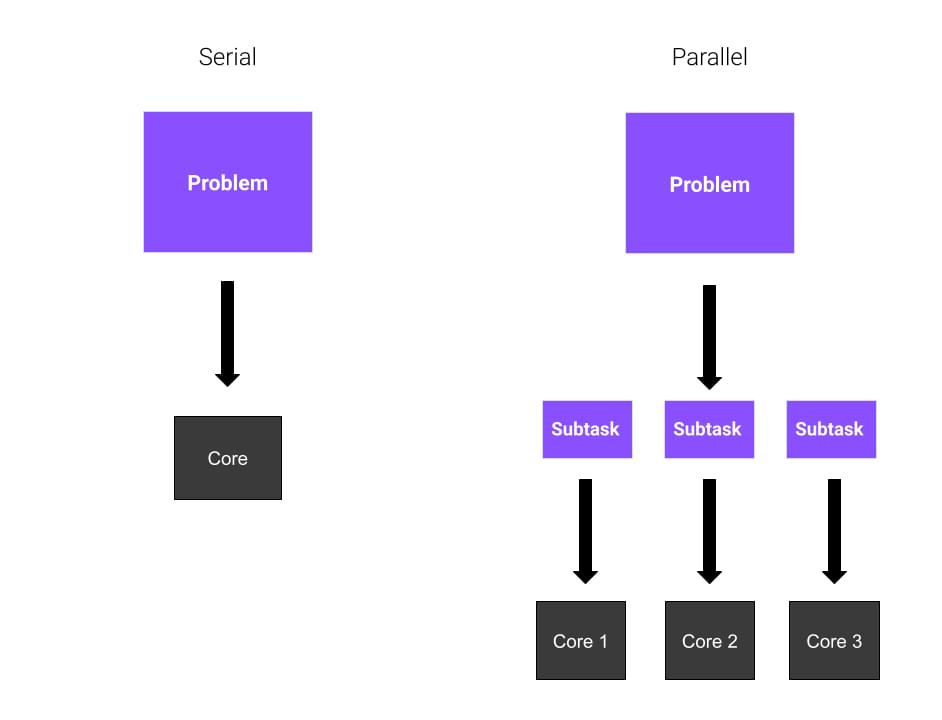
Parallel and Serial Computing
Imagine you have a huge problem to solve, and you’re alone. You need to calculate the square root of eight different numbers. What do you do? Well, you don’t have many options. You start with the first number, and you calculate the result. Then, you go on with the others.
What if you have three friends good at math willing to help you? Each of them will calculate the square root of two numbers, and your job will be easier because the workload is distributed equally between your friends. This means that your problem will be solved faster.
Okay, so all clear? In these examples, each friend represents a core of the CPU. In the first example, the entire task is solved sequentially by you. This is called serial computing. In the second example, since you’re working with four cores in total, you’re using parallel computing. Parallel computing involves the usage of parallel processes or processes that are divided among multiple cores in a processor.
Models for Parallel Programming
We’ve established what parallel programming is, but how do we use it? Well, we said before that parallel computing involves the execution of multiple tasks among multiple cores of the processor, meaning that those tasks are executed simultaneously. There are a few questions that you should consider before approaching parallelization. For example, are there any other optimizations that could speed up our computations?
For now, let’s take for granted that parallelization is the best solution for you. There are mainly three models in parallel computing:
- Perfectly parallel. The tasks can be run independently, and they don’t need to communicate with each other.
- Shared memory parallelism. Processes (or threads) need to communicate, so they share a global address space.
- Message passing. Processes need to share messages when needed.
In this article, we’ll illustrate the first model, which is also the simplest.
Python Multiprocessing: Process-based Parallelism in Python
One way to achieve parallelism in Python is by using the multiprocessing module. The multiprocessing module allows you to create multiple processes, each of them with its own Python interpreter. For this reason, Python multiprocessing accomplishes process-based parallelism.
You might have heard of other libraries, like threading, which also comes built-in with Python, but there are crucial differences between them. The multiprocessing module creates new processes, while threading creates new threads.
In the next section, we’ll look at the advantages of using multiprocessing.
Benefits of Using Multiprocessing
Here are a few benefits of multiprocessing:
- better usage of the CPU when dealing with high CPU-intensive tasks
- more control over a child compared with threads
- easy to code
The first advantage is related to performance. Since multiprocessing creates new processes, you can make much better use of the computational power of your CPU by dividing your tasks among the other cores. Most processors are multi-core processors nowadays, and if you optimize your code you can save time by solving calculations in parallel.
The second advantage looks at an alternative to multiprocessing, which is multithreading. Threads are not processes though, and this has its consequences. If you create a thread, it’s dangerous to kill it or even interrupt it as you would do with a normal process. Since the comparison between multiprocessing and multithreading isn’t in the scope of this article, I encourage you to do some further reading on it.
The third advantage of multiprocessing is that it’s quite easy to implement, given that the task you’re trying to handle is suited for parallel programming.
Getting Started with Python Multiprocessing
We’re finally ready to write some Python code!
We’ll start with a very basic example and we’ll use it to illustrate the core aspects of Python multiprocessing. In this example, we’ll have two processes:
- The
parentprocess. There’s only one parent process, which can have multiple children. - The
childprocess. This is spawned by the parent. Each child can also have new children.
We’re going to use the child process to execute a certain function. In this way, the parent can go on with its execution.
A simple Python multiprocessing example
Here’s the code we’ll use for this example:
from multiprocessing import Process def bubble_sort(array): check = True while check == True: check = False for i in range(0, len(array)-1): if array[i] > array[i+1]: check = True temp = array[i] array[i] = array[i+1] array[i+1] = temp print("Array sorted: ", array) if __name__ == '__main__': p = Process(target=bubble_sort, args=([1,9,4,5,2,6,8,4],)) p.start() p.join()
In this snippet, we’ve defined a function called bubble_sort(array). This function is a really naive implementation of the Bubble Sort sorting algorithm. If you don’t know what it is, don’t worry, because it’s not that important. The crucial thing to know is that it’s a function that does some work.
The Process class
From multiprocessing, we import the class Process. This class represents an activity that will be run in a separate process. Indeed, you can see that we’ve passed a few arguments:
target=bubble_sort, meaning that our new process will run thebubble_sortfunctionargs=([1,9,4,52,6,8,4],), which is the array passed as argument to the target function
Once we’ve created an instance to the Process class, we only need to start the process. This is done by writing p.start(). At this point, the process is started.
Before we exit, we need to wait for the child process to finish its computations. The join() method waits for the process to terminate.
In this example, we’ve created only one child process. As you may guess, we can create more child processes by creating more instances in the Process class.
The Pool class
What if we need to create multiple processes to handle more CPU-intensive tasks? Do we always need to start and wait explicitly for termination? The solution here is to use the Pool class.
The Pool class allows you to create a pool of worker processes, and in the following example, we’ll look at how can we use it. This is our new example:
from multiprocessing import Pool
import time
import math N = 5000000 def cube(x): return math.sqrt(x) if __name__ == "__main__": with Pool() as pool: result = pool.map(cube, range(10,N)) print("Program finished!")
In this code snippet, we have a cube(x) function that simply takes an integer and returns its square root. Easy, right?
Then, we create an instance of the Pool class, without specifying any attribute. The pool class creates by default one process per CPU core. Next, we run the map method with a few arguments.
The map method applies the cube function to every element of the iterable we provide — which, in this case, is a list of every number from 10 to N.
The huge advantage of this is that the calculations on the list are done in parallel!
Making Best Use of Python Multiprocessing
Creating multiple processes and doing parallel computations is not necessarily more efficient than serial computing. For low CPU-intensive tasks, serial computation is faster than parallel computation. For this reason, it’s important to understand when you should use multiprocessing — which depends on the tasks you’re performing.
To convince you of this, let’s look at a simple example:
from multiprocessing import Pool
import time
import math N = 5000000 def cube(x): return math.sqrt(x) if __name__ == "__main__": start_time = time.perf_counter() with Pool() as pool: result = pool.map(cube, range(10,N)) finish_time = time.perf_counter() print("Program finished in {} seconds - using multiprocessing".format(finish_time-start_time)) print("---") start_time = time.perf_counter() result = [] for x in range(10,N): result.append(cube(x)) finish_time = time.perf_counter() print("Program finished in {} seconds".format(finish_time-start_time))
This snippet is based on the previous example. We’re solving the same problem, which is calculating the square root of N numbers, but in two ways. The first one involves the usage of Python multiprocessing, while the second one doesn’t. We’re using the perf_counter() method from the time library to measure the time performance.
On my laptop, I get this result:
> python code.py
Program finished in 1.6385094 seconds - using multiprocessing
---
Program finished in 2.7373942999999996 seconds
As you can see, there’s more than one second difference. So in this case, multiprocessing is better.
Let’s change something in the code, like the value of N. Let’s lower it to N=10000 and see what happens.
This is what I get now:
> python code.py
Program finished in 0.3756742 seconds - using multiprocessing
---
Program finished in 0.005098400000000003 seconds
What happened? It seems that multiprocessing is now a bad choice. Why?
The overhead introduced by splitting the computations between the processes is too much compared to the task solved. You can see how much difference there is in terms of time performances.
Conclusion
In this article, we’ve talked about the performance optimization of Python code by using Python multiprocessing.
First, we briefly introduced what parallel computing is and the main models for using it. Then, we started talking about multiprocessing and its advantages. In the end, we saw that parallelizing the computations is not always the best choice and the multiprocessing module should be used for parallelizing CPU-bound tasks. As always, it’s a matter of considering the specific problem you’re facing and evaluating the pros and cons of the different solutions.
I hope you’ve found learning about Python multiprocessing as useful as I did.