
Components are great, aren’t they? They are these reusable sources of truth that you can use to build rock-solid front-ends without duplicating code.
You know what else is super cool? Headless content management! Headless content management system (CMS) products offer a content editing experience while freeing that content in the form of data that can be ported, well, to any API-consuming front-end UI. You can structure your content however you’d like (depending on the product), and pull that content into your front-end applications.
Using these two things together — a distributed CMS solution with component-based front-end applications — is a core tenet of the Jamstack.
But, while components and headless CMSs are great on their own, it can be difficult to get them to play nicely together. I‘m not saying it‘s difficult to hook one up to the other. In a lot of cases, it’s actually quite painless. But, to craft a system of components that is reusable and consistent, and to have that system maintain parity with a well-designed CMS experience is a difficult thing to achieve. It’s that win-win combo of being able to freely write content and then have that content structured into predictable components that makes headless content management so appealing.
Achieving parity between a CMS and front-end components
Table of Contents
My favorite demonstrating this complexity is a simple component: a button. Let‘s say we’re working with React to build components and our button looks like this:
<Button to="/">Go Home</Button>In the lovely land of React, that means the <Button> component has two props (i.e. properties, attributes, arguments, etc.) — to and children. children is a React thing that holds all the content within the opening and closing tags, which is “Go Home” in this case.)
If we’re going to enable users in the content editor to add buttons to the site, we want a system for them that makes it easy to understand how their actions in the CMS affect what appears on screen in the front-end app. But we also want our developer(s) to work productively with component properties that make sense to them and within the framework they’re working (i.e. React in our example).
How do we do that?
We could…
…use fields in the CMS that match the components’ properties, though I’ve had little success with this approach. to and children don‘t make much sense to content editors trying to build a button. Believe me, I‘ve tried. I‘ve tried with beginners and experienced editors alike. I‘ve tried helper text. It doesn’t matter. It’s confusing.
What makes more sense is using words editors are more likely to understand, like label or text for children and url for to.
But then we’d be out of sync with our code.
Or what if we…
…masked attributes in the CMS. Most headless CMS solutions enable you to have a different value for the label of the field than the name that is used when delivering content via an API.
We could label our fields Label and URL, but use children and to as the names. We could. But we probably shouldn’t. Remember what Ian Malcolm said?
On the surface, masking attributes makes sense. It’s a separation of concerns. The editors see something that makes them happy and productive, and the developers work with the names that make sense to them. I like it, but only in theory. In practice, it confuses developers. Debugging a content editor issue often requires digging through extra layers (i.e. time) to find the relationship between labels and field names.
Or why not …
…change the properties. Wouldn’t it be easier for developers to be flexible? They’re the ones designing the system, after all.
Yes, that’s true. But if you follow that rule exclusively, it’s inevitable that you’re going to run into some issue along the way. You’ll likely end up fighting against the framework, or props will just feel goofy.
In our example, using label and url as props for a button works totally fine for data that originates from the CMS. But that also means that any time our developers want to use a button within the code, it looks like this:
<Button label="Go Home" url="/" />That may seem okay on the surface, but it significantly limits the power of the button. Let’s say I want to support some other feature, like adding an icon within the label. I’m going to need some additional logic or another property for it. If I would have used React’s children approach instead, it would have just worked (likely after some custom styling support).
Okay, so… what do we do?
Introducing transformers
The best approach I’ve found is to separately optimize the editor and developer experiences. Craft a CMS experience that is catered to the editors. Build a codebase that is easy for developers to navigate, understand, and enhance.
The result is that the two experiences will not be in parity with one another. We need some set of utilities to transform the data from the CMS structure into something that can be used by the front-end, regardless of the framework and tooling you’re using.
I call these utilities transformers. (Aren’t I so good at naming things!?) Transformers are responsible for consuming data from your CMS and transforming it into a shape that can be easily consumed by your components.
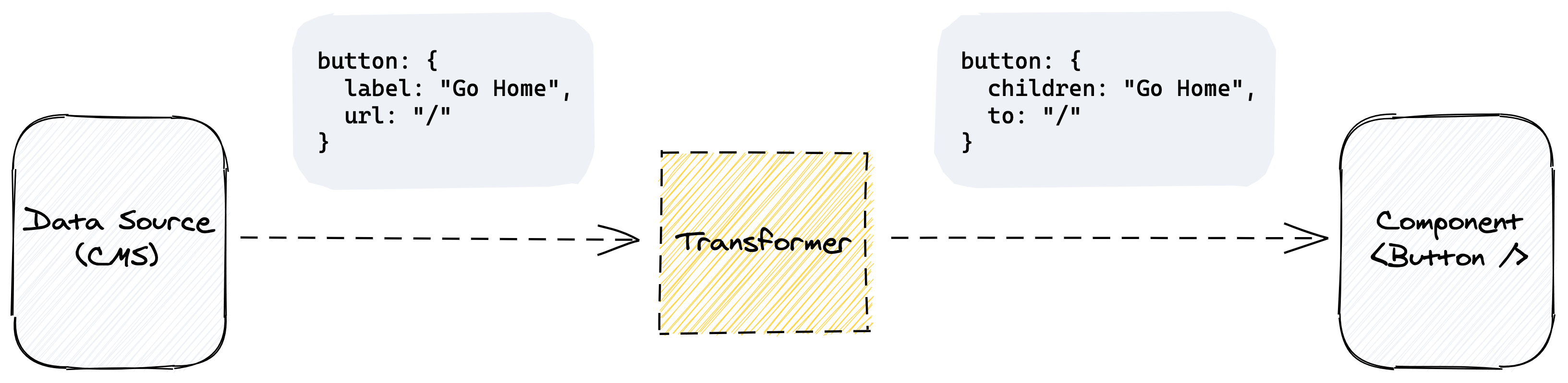
While I‘ve found that transforming data is the smoothest means to get great experiences in both the CMS and the codebase, I don‘t have an obvious solution for how (or perhaps where) those transformations should happen. I‘ve used three different approaches, all of which have their pros and cons. Let’s take a look at them.
1. Alongside components
One approach is to put transformers right alongside the components they are serving. This is the approach I typically take in organizing component-based projects — to keep related files close to one another.
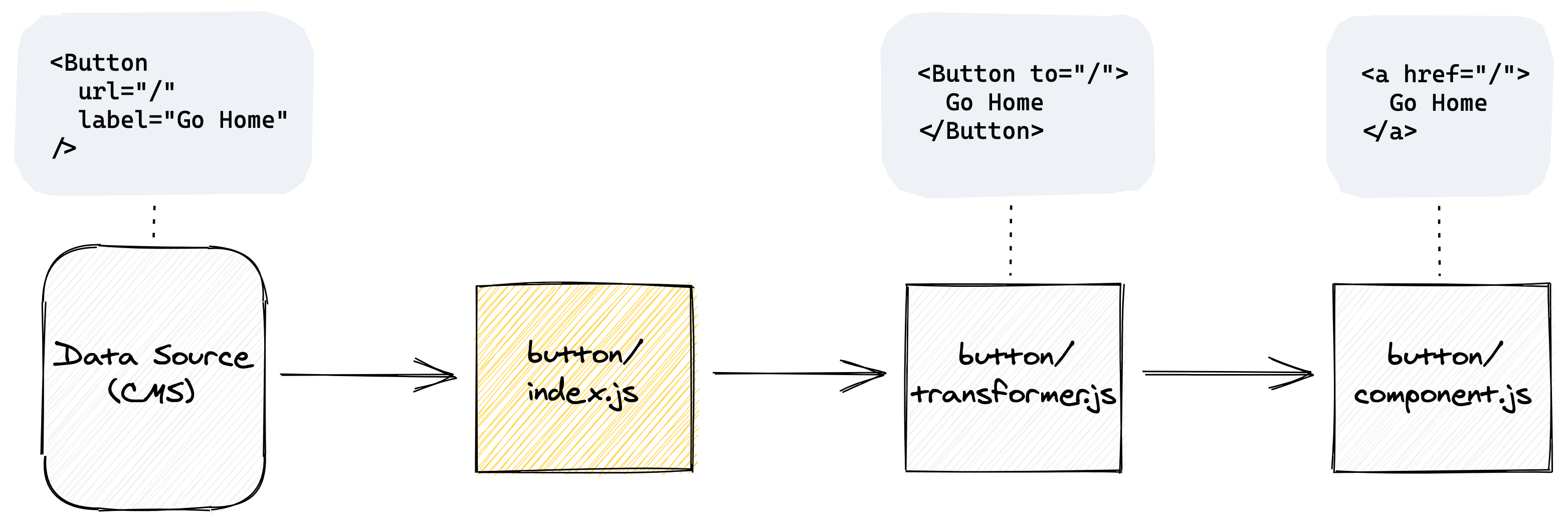
That means that I often have a directory for every component with a predictable set of files. The index.js acts as the controller for the component. It is responsible for importing and exporting all other relevant files. That makes it trivial to wrap the component with some logic-based behavior. In other words, it could transform properties of the component before rendering it. Here’s what that might look like for our button example:
import React from "react" import Component from "./component"
import transform from "./transformer" const Button = props => <Component {...transform(props)} /> export default ButtonThe transform.js file might look like this:
export default input => { return { ...input, children: input.children || input.label, to: input.to || input.url }
}In this example, if to and children were properties sent to the component, it works just fine! But if label and url were used instead, they are transformed to children and to. That means the <Button> component (component.js) only has to worry about using children and to.
const Button = ({ children, to }) => <a href={to}>{children}</a>I personally love this approach. It keeps the logic tightly coupled with the component. The biggest downside I‘ve found thus far is that it’s a large number of files and transforms, when the entire dataset for any given page could be transformed earlier in the stack, which would be…
2. At the top of the funnel
The data has to be pulled into the application via some mechanism. Developers use this mechanism to retrieve as much data for the current page or view as possible. Often, the fewer number of queries/requests a page is required to make, the better its performance.
In other words, that mechanism often exists near the top of the funnel (or stack), as opposed to each component pulling its own data in dynamically. (When that’s necessary, I use adapters.)
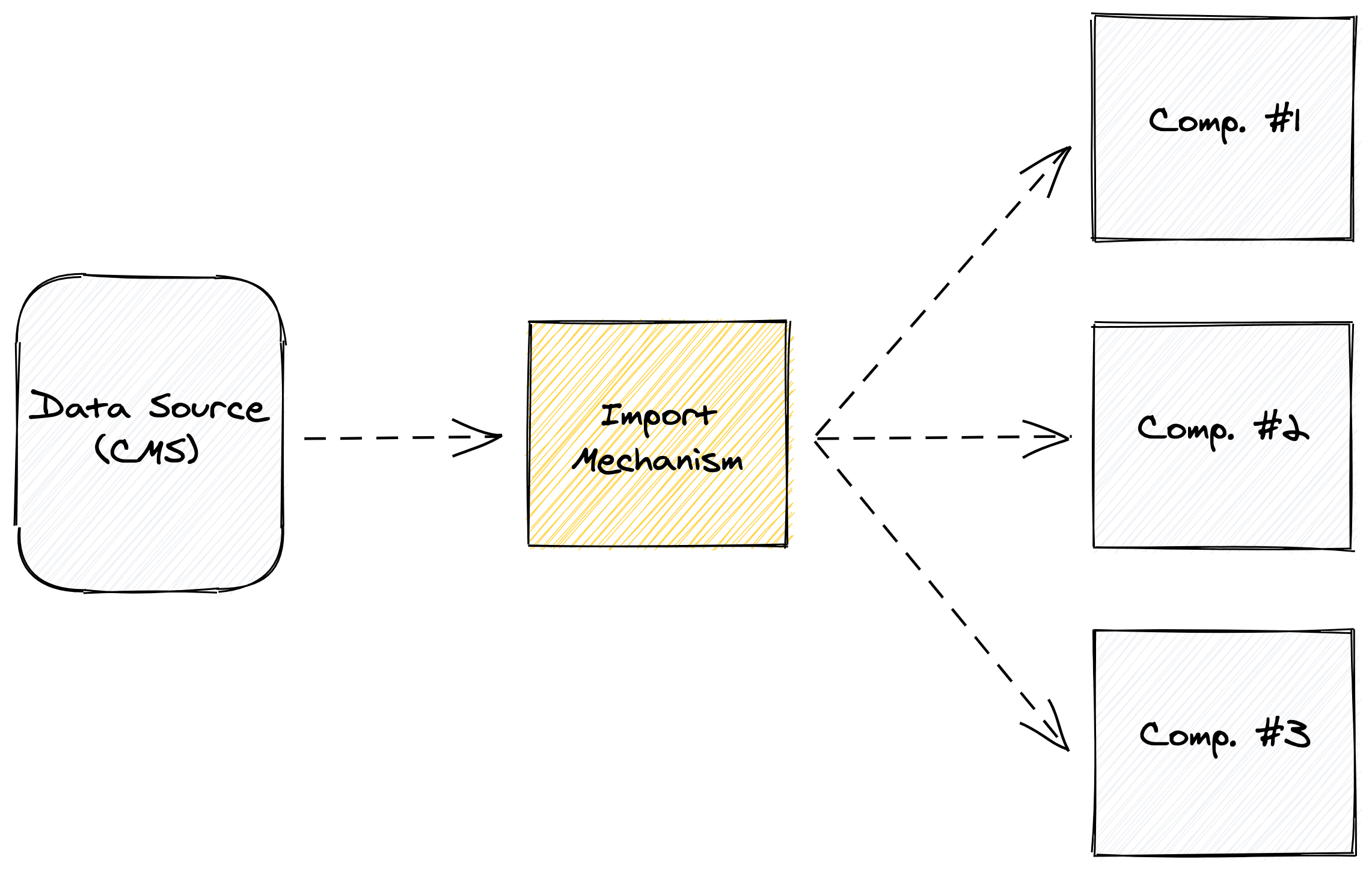
The mechanism that retrieves the page data could also be responsible for transforming all the data for the given page before it renders any of its components.
In theory, this is a better approach than the first one. It decreases the amount of work the browser has to do, which should improve the front-end performance. That means the server has to do more work, but that’s often a better choice.
In practice, though, this is a lot of work. Data structures can be big, complex, and interwoven. It can take a heck of a lot of work to transform everything into the right format at the top of the funnel, and then pass the transformed data down to components. It’s also more difficult to test because of the potential complexity and variation of the giant data blob retrieved at the top of the stack. With the first approach, testing the transformer logic for the button is trivial. With this approach, you’d want to account for transforming button data anywhere that it might appear in the retrieved data object.
But, if you can pull it off, this is generally the better approach.
3. The middleman engine
The third and final (and magical) approach is to do all this work somewhere else. In this case, we could build an engine (i.e. a small application) that would do the transformations for us, and then make the content available for the application to consume.
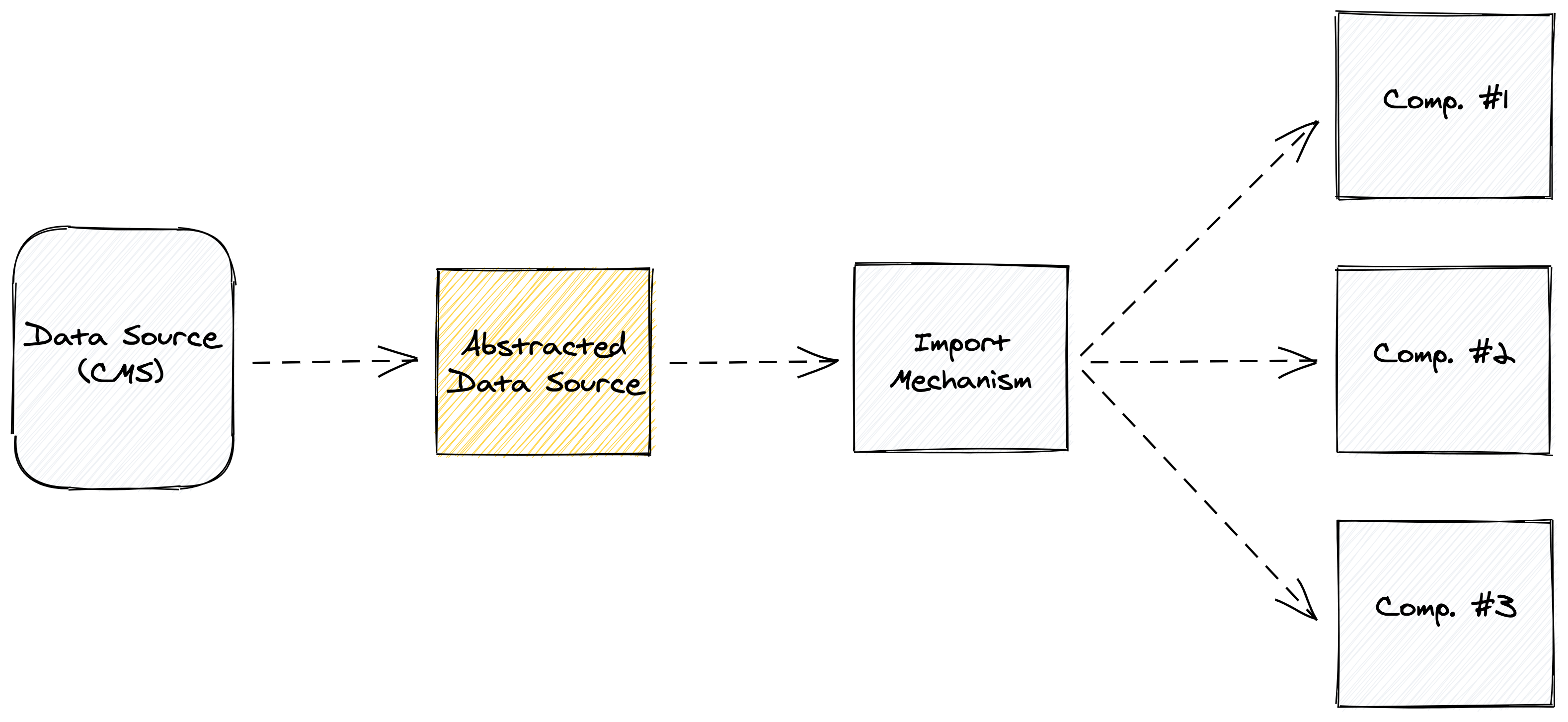
This is likely even more work than the second approach. And it has added cost and maintenance in running an additional application, which takes more effort to ensure it is rock solid.
The major upside to this approach is that we could build this as an abstracted engine. In other words, any time we bring in data to any front-end application, it goes through this middleman engine. That means if we have two projects that use the same CMS or data source, our work is cut down significantly for the second project.
If you aren‘t doing any of this today and want to start, my advice is to treat these approaches like stepping stones. They grow in complexity and maintenance and power as the application grows. Start with the first approach and see how far that gets you. Then, if you feel like you could benefit from a jump to the second, do it! And if you’re feeling like living dangerously, go for the third!
In the end, what matters most is crafting an experience that both your editors and your developers understand and enjoy. If you can do that, you win!


