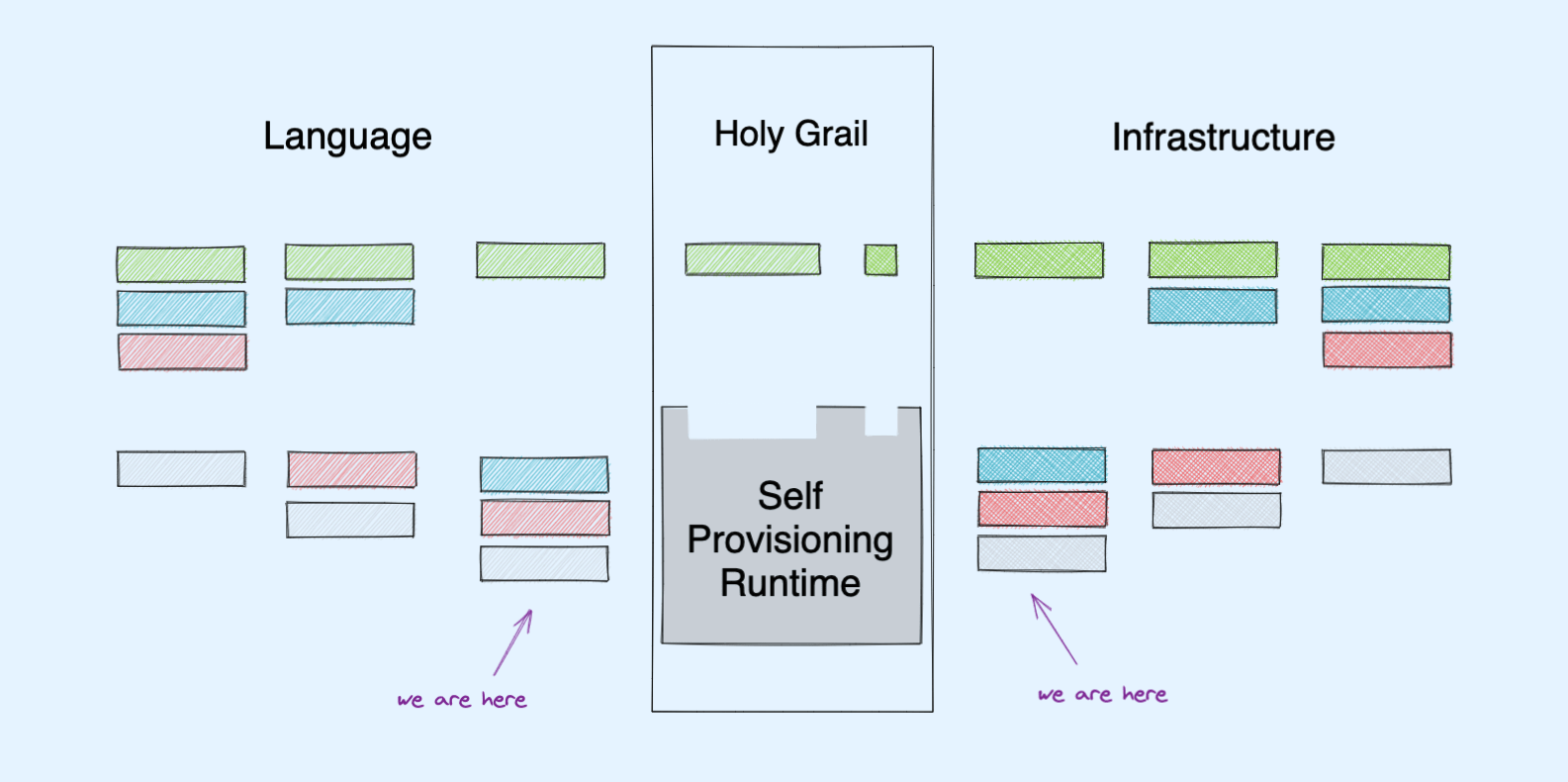
If the Platonic ideal of Developer Experience is a world where you “Just Write Business Logic”, the logical endgame is a language+infrastructure combination that figures out everything else.
Two paraphrases as assertions:
- People who are really serious about developer experience should make their own language or runtime. (quote)
- Developer Experience advances by extending the number of important problems our code handles without thinking of them. (quote)
I feel a strong intuition of what the future of programming languages holds for practical (non-academic) developers, but lack the formal background to fully specify it. I’ll write down the parts of the elephant I feel, and hope that the rest is so obvious that you, dear reader, shout and scream at me to fill in the blanks of my ignorance. Please get in touch!!! My ignorance could fill a (blank) book and I need to know who to follow and what to read.
My central assertion: Advancements in two fields — programming languages and cloud infrastructure — will converge in a single paradigm: where all resources required by a program will be automatically provisioned, and optimized, by the environment that runs it.
I am going to grossly oversimplify in order to make a point, which will infuriate some of you. I apologize in advance. It bothers me too but I did it anyway to strip out noise. If you have better examples to offer, please get in touch!
One of Java’s key advantages over C++ was its automatic garbage collection, whereas one of Go’s key advantages over Java is its native CSP model. At a 50,000 ft view you can see languages as advancing by the number of hard problems that are elegantly solved by convention or language feature.
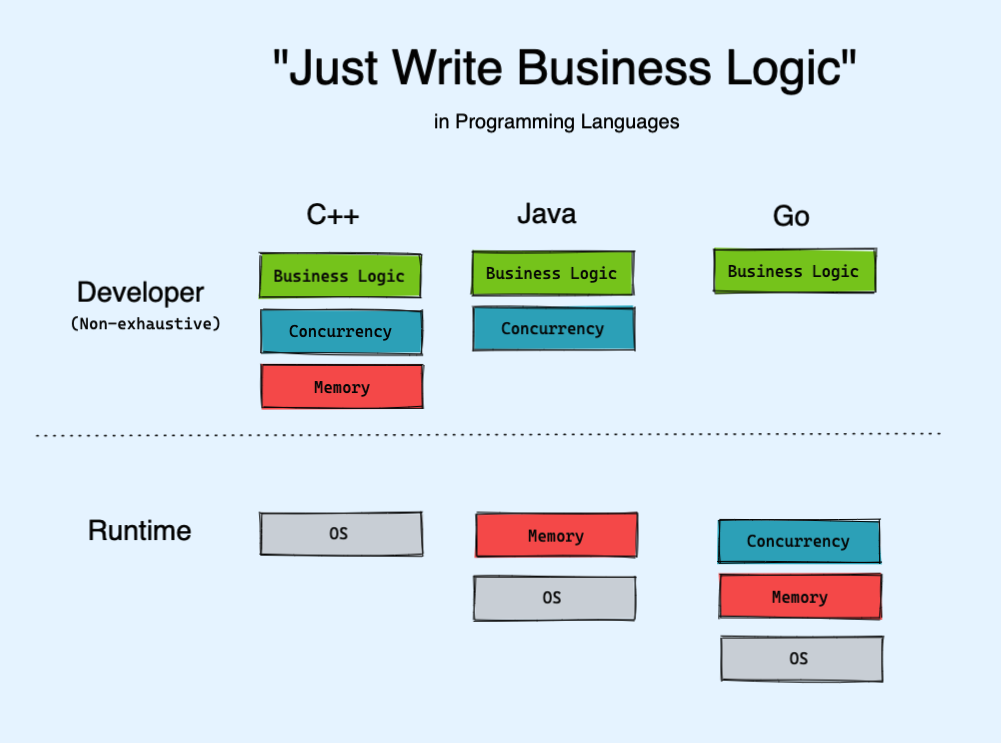
I’ve drawn the above chart as though Go is the perfect end state of things, but I want you to know that that is more due to my own lack of knowledge about what else could be abstracted. Please improve it if you can and I’ll update and credit you. Adrian Colyer also has this work of art which should satisfy the more rigorously inclined:
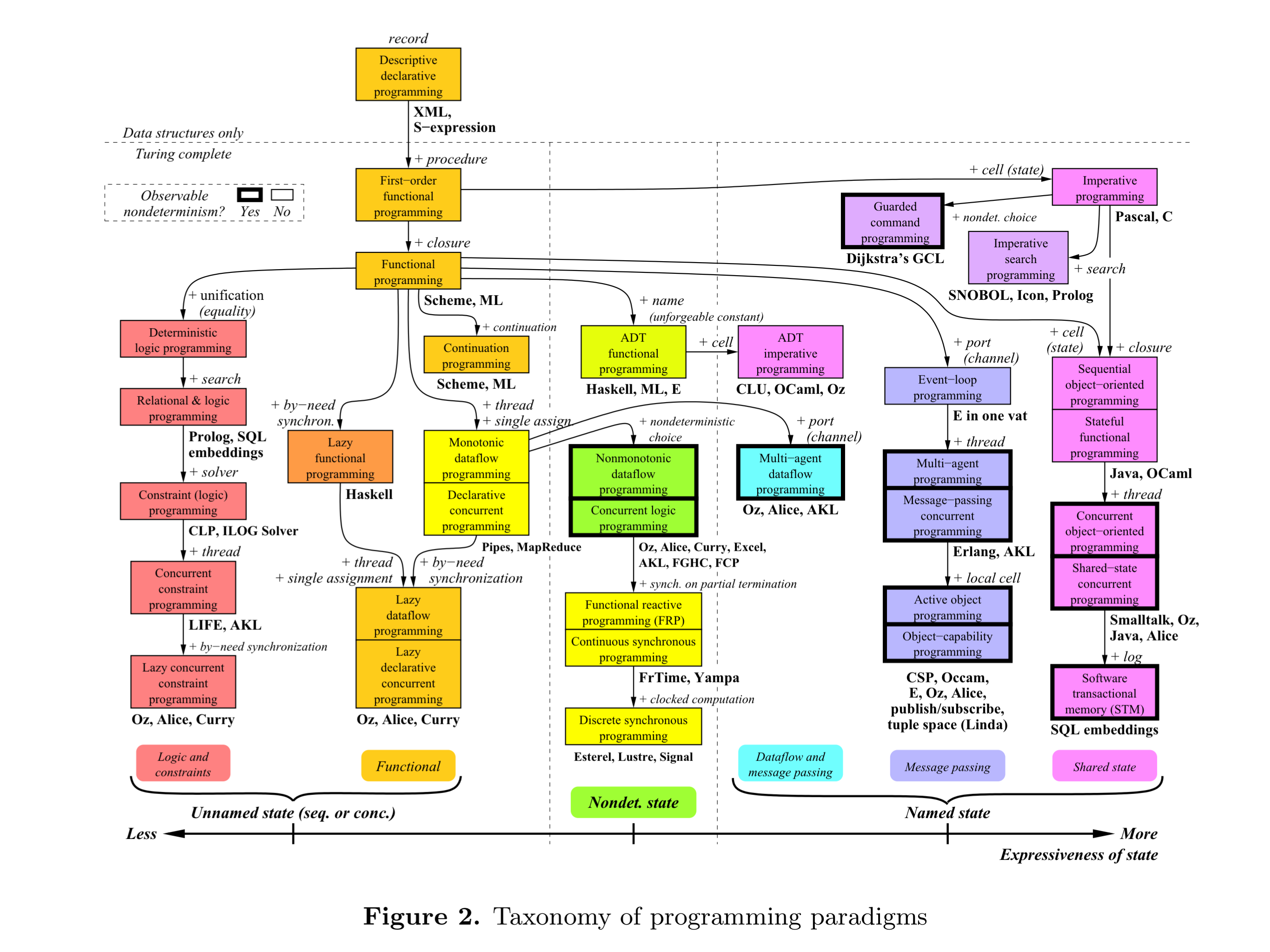
In my oversimplistic interpretation, programming language advancement (and improvement in developer experience) could be viewed as the identification of programming chores that can be cleanly extracted into some shared codebase/convention with almost no loss in power.
If we can clearly define a new chore, we can make it a language feature.
A “language paradigm” doesn’t have to be a standalone, full fledged new-parser-lexer-required programming language to do this job. Every framework, from React to Rails, parasitically imposes its own grammar and rules atop a host language, and good API design is indistinguishable from language design. (I gave a talk on React-as-Language last year if you are interested in more on this.)
However, language development to date has mostly proceeded agnostic to infrastructure concerns, at the exact same time when infrastructure engineers are embracing languages to solve their problems.
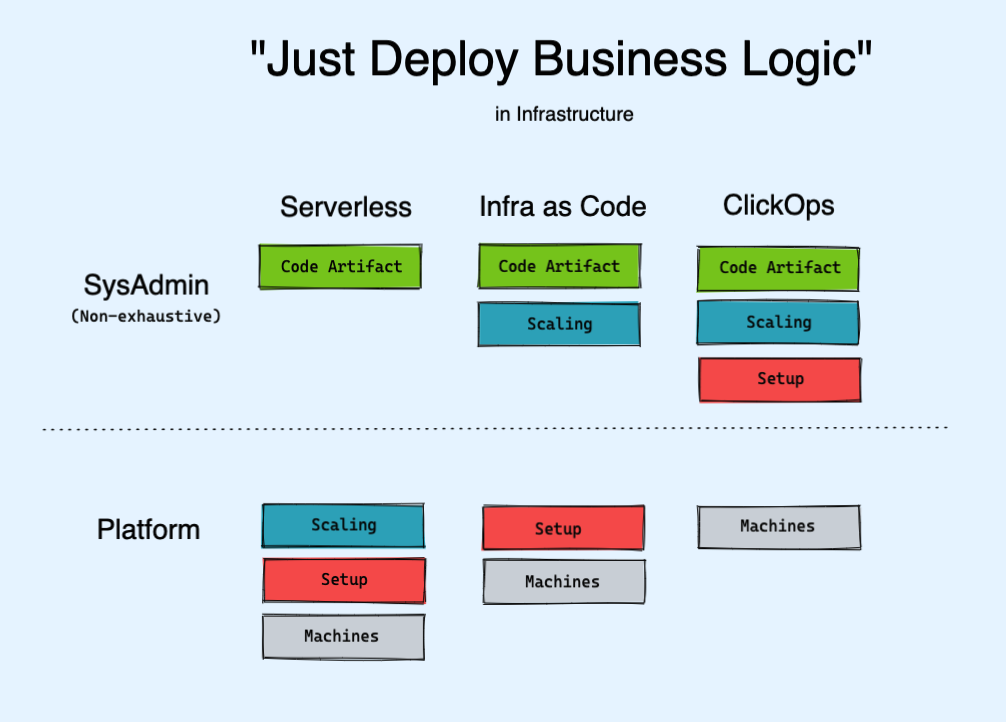
What we lost when we broke up the monolith to move to the cloud was the assumption that everything our program needed would be in the box our program ran in. Suddenly we needed to provision storage, databases, VMs, containers, clusters, message queues, identity providers, gateways, and more and more and more vendor logos.
Managing all this by hand was impossible, so we moved toward declarative infrastructure, variously called Programmable Infrastructure or Infrastructure as Code:
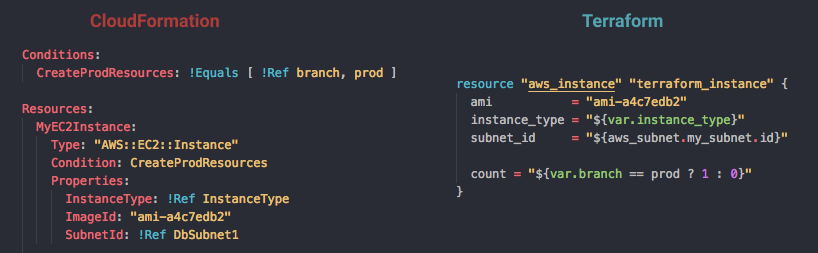
This works until you are knee deep in 30 minute debug loops pushing thousands of lines of YAML to see if this time it’ll work, and start wishing for mature software engineering tooling like testing, code reuse, and linting/completions. At least that’s how I see AWS CDK:
The serverless movement started off with simple stateless functions like AWS Lambda, but with the advent of container based solutions like AWS Fargate and Google Cloud Run, “serverless” has now come to mean autoscaling. This was another “chore” that is now increasingly part of every DevOps toolkit:
(Edit this chart)
But, just like with languages, there are new chores to be found. The original intent of the DevOps movement was getting Devs to do their own Ops, but it feels like the outcome was mostly Ops people doing more Dev to keep up with the Joneses. If DevOps was successful enough, or if platforms were good enough at their jobs, Ops work should disappear.
With a cutting edge stack today, you can fully describe your AWS Infrastructure in TypeScript, and write your application code in TypeScript… but yet these are separately executed and run things, with gobs of glue code between them (both explicit, in the form of connection strings, resource identifiers and client secrets, and implicit, in the form of SDKs).
Check out this example (from my former team at AWS! no diss intended at all). Here’s just a glimpse of the Infra setup code:
// // Infra code
// lib/next-backend-stack.ts
import * as cdk from '@aws-cdk/core'
import * as cognito from '@aws-cdk/aws-cognito'
import * as appsync from '@aws-cdk/aws-appsync'
import * as ddb from '@aws-cdk/aws-dynamodb'
import * as lambda from '@aws-cdk/aws-lambda' // lib/next-backend-stack.ts
const api = new appsync.GraphqlApi(this, 'cdk-blog-app', {
name: "cdk-blog-app",
logConfig: {
fieldLogLevel: appsync.FieldLogLevel.ALL,
},
schema: appsync.Schema.fromAsset('./graphql/schema.graphql'),
authorizationConfig: {
defaultAuthorization: {
authorizationType: appsync.AuthorizationType.API_KEY,
apiKeyConfig: {
expires: cdk.Expiration.after(cdk.Duration.days(365))
}
},
additionalAuthorizationModes: [{
authorizationType: appsync.AuthorizationType.USER_POOL,
userPoolConfig: {
userPool,
}
}]
},
})
// Create the function
const postLambda = new lambda.Function(this, 'AppSyncPostHandler', {
runtime: lambda.Runtime.NODEJS_14_X,
handler: 'main.handler',
code: lambda.Code.fromAsset('lambda-fns'),
memorySize: 1024
}) // Set the new Lambda function as a data source for the AppSync API
const lambdaDs = api.addLambdaDataSource('lambdaDatasource', postLambda)
And a glimpse at the app code:
const AWS = require('aws-sdk')
const docClient = new AWS.DynamoDB.DocumentClient() async function getPostById(postId: string) {
const params = {
TableName: process.env.POST_TABLE,
Key: { id: postId }
}
try {
const { Item } = await docClient.get(params).promise()
return Item
} catch (err) {
console.log('DynamoDB error: ', err)
}
} export default getPostById
That’s still an awful lot of code between your app and its platform.
What will it take to “just write business logic” and have the platform figure out the rest?
(Edit this chart)
On a very trivial basis, we already have this. Where Heroku used to require buildpacks, most PaaS platforms now have heuristics that determine the project type for build and environment setup, automatically adapting for when you have a Gemfile, requirements.txt, .nvmrc, or docker-compose.yml. Platforms like Netlify and Vercel are going deeper than language runtimes, detecting frameworks and static site generators, but they are still mostly focused on build dependencies.
Self-provisioning can go further than just smarter build automation:
- Imagine if you could provision a DynamoDB table by just requiring
@begin/datain your app code (similar but not exactly like Begin Data!) - Vercel and Netlify set up serverless functions based on Next.js routes and specially designated folders.
- Netlify Forms scan your generated HTML and provisions any form endpoints and storage needed (see my old Gatsby demo here to see it in action or my recent one with Svelte)
- Pulumi isn’t automatic but combines app and provisioning logic in a very neatly concise way that would basically function as though the provisioning and app logic were actually one.
- Serverless Cloud is working on “Infrastructure from Code” – Contact Jeremy Daly and Doug Moscrop.
- Aldo Bucchi is working on Lambdragon: “Standing on the shoulders of giants (Pulumi’s closure serialization approach, Temporal/Cadence’s long running processes, Graal’s multi-runtime JIT engine) and borrowing from academia when necessary for things like async transactional boundaries and type checking of heterogeneous codebases, we’ve spent he last two years solving all of these problems from the ground up so we can deliver a true “universal, automatically inferred runtime”.”
- (Stealth startup) is building endpoints from statically analyzing JavaScript.
- Wasp-lang is a (very) new startup trying to combine React routing and the Prisma schema together in a DSL.
- Encore.dev by Andre Eriksson – “Call APIs as functions” and “Automatically managed PostgreSQL databases”
- Cloud Compiler maybe… still super early
All this only scratches the surface of what is possible when you merge language and infrastructure. If you go down the list of Jobs to Be Done of a Cloud you can see all of these can be automatically provisioned as part of the language.
Part of my original Temporal pitch made reference to the fact that you could dynamically create retries, timeouts, task queues and timers in your application code, and Temporal would take care of it for you.
For the first time ever: self provisioning asynchrony.
// retries and timeouts handled declaratively
export async function main(): Promise<void> {
const child = Context.child('wf name', {
taskQueue: 'test',
workflowExecutionTimeout: '10ms',
retryPolicy: { maximumAttempts: 1 },
});
await child.execute();
} // task queue dynamically provisioned
const workflow = workflowClient.stub('my-workflow', {
taskQueue: 'my-task-queue',
});
const result = await workflow.execute(); // durable timer used inline with code
let hasUserResponded = false
await Promise.race([
async () => waitForUser().then(() => hasUserResponded = true),
sleep(7 * DAYS) // durably set timer for 1 week!
]);
if (!hasUserResponded) // ... remind user or something
When you can freely and reliably move code into async blocks without the hassle of extra provisioning, the cost of building out new business logic features becomes dramatically cheaper. This is a subtle point, so I’m going to give you an example (told by Joel Spolsky, featured on my mixtape):
When Jeff Bezos wanted to turn the Amazon buying experience into a one click purchase, the engineers struggled to make it one click – their minds were set around the synchronous request-response, shopping-cart and order-confirmation model. The big unlock to One Click Purchases was accepting purchases right away, and setting a timer for them to change their mind. A lot of user experiences are improved by turning synchronous things asynchronous, and racing human interaction against timers, but previously the barrier to do this would be very high because of extra infrastructure involved. Self-provisioning is key to lowering the barriers to experimentation and feature development.
Because Temporal Server already contains the infrastructure to handle tasks and timers, Temporal users can essentially offload that problem to a central “Platform” or “Infrastructure” team. Still, as of today this cannot be considered fully self-provisioning, because Temporal still relies on manual monitoring and scaling (this is the central problem that Temporal Cloud solves).
Besides, reliable async primitives are great, but far from the totality of infrastructure that a modern app requires. I want ONE paradigm that auto-provisions ALL of it based on the code I write.
Does it have to be a new language? This is what Paul Biggar is working on with Darklang, where Datastores are colocated with HTTP routing and Cron and Functions:
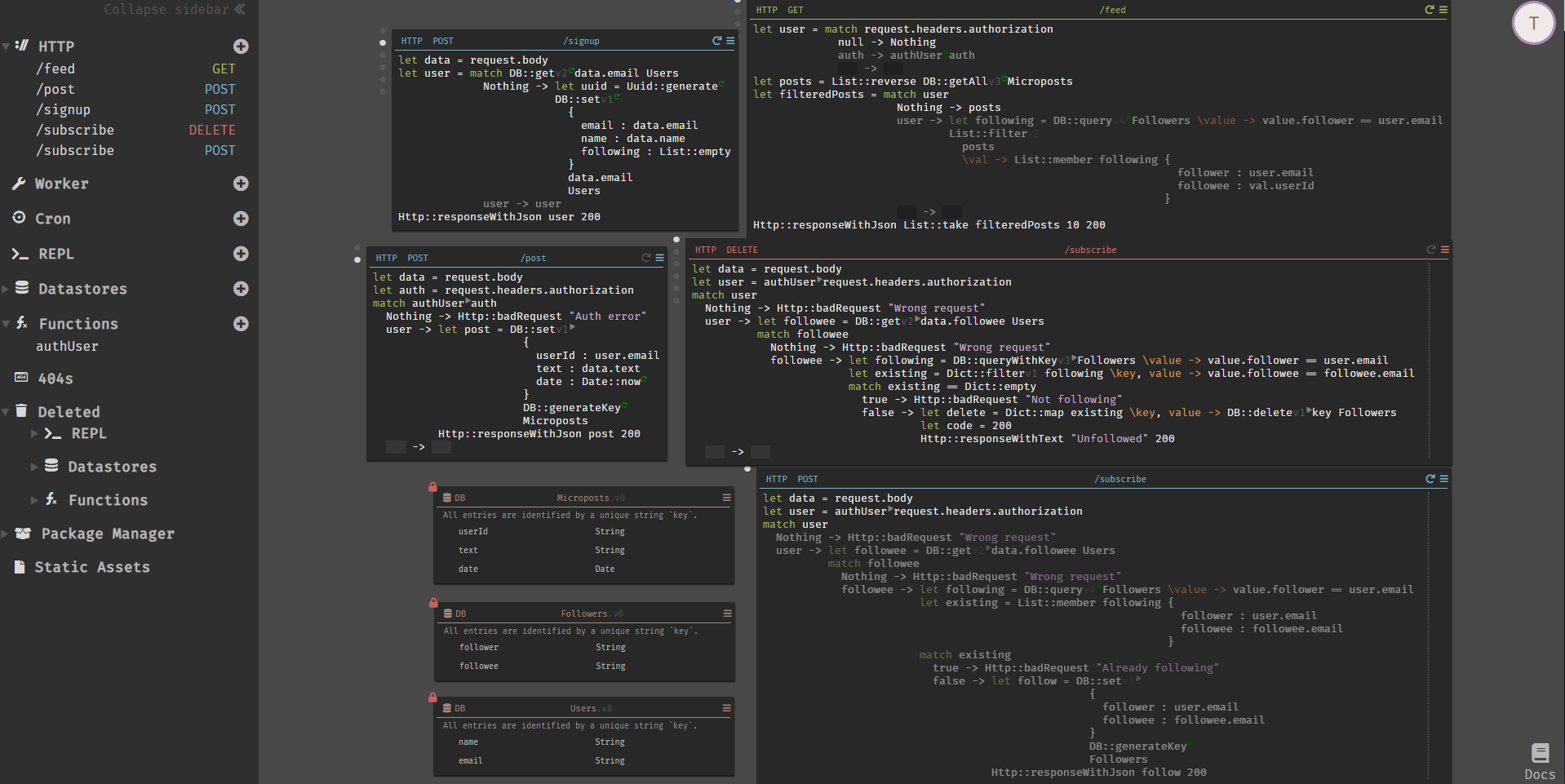
You not only can’t code against a database that doesn’t exist, you can’t even code against traffic that doesn’t exist, ensuring your code is always valid (within Dark’s universe).
Even if Dark is too strict for you (as it is for most), you could imagine taking advantage of a strongly typed, purposefully designed language that can be statically analyzed for all its infrastructural dependencies, which then translates to the necessary resource languages of the big clouds.
Jolie Lang is another effort I’ve come across here, though not so much self-provisioning as it is infrastructure agnostic, which I’m not really convinced solves anyone’s problems but check it out and tell me if you think otherwise.
My sense is it doesn’t have to be a new language. Imposing special rules on execution and syntax, and taking over the compiler or runtime — we even call our engineers Language Runtime Engineers — may be enough.
Runtime optimizations are also a huge opportunity for dynamic (not static + upfront) self-provisioning: after all, what is serverless but a self-provisioning runtime based on traffic?
People are wondering if there is still anything left to innovate in programming languages, but I write because I am almost certain that there is. But before we get there, the right move is probably a self provisioning runtime where we can prototype all these ideas – at the intersection of language and infrastructure.
Chris Coyier chimes in with his take on the Self Provisioning Runtime!