Being able to understand Node continues to be an important skill if you’re a front-end developer. Deno has arrived as another way to run JavaScript outside the browser, but the huge ecosystem of tools and software built with Node mean it’s not going anywhere anytime soon.
If you’ve mainly written JavaScript that runs in the browser and you’re looking to get more of an understanding of the server side, many articles will tell you that Node JavaScript is a great way to write server-side code and capitalize on your JavaScript experience.
I agree, but there are a lot of challenges jumping into Node.js, even if you’re experienced at authoring client-side JavaScript. This article assumes you’ve got Node installed, and you’ve used it to build front-end apps, but want to write your own APIs and tools using Node.
For a beginners explanation of Node and npm you can check out Jamie Corkhill’s “Getting Started With Node” on Smashing Magazine.
Asynchronous JavaScript
Table of Contents
We don’t need to write a whole lot of asynchronous code on the browser. The most common usage of asynchronous code on the browser is fetching data from an API using fetch (or XMLHttpRequest if you’re old-school). Other uses of async code might include using setInterval, setTimeout, or responding to user input events, but we can get pretty far writing JavaScript UI without being asynchronous JavaScript geniuses.
If you’re using Node, you will nearly always be writing asynchronous code. From the beginning, Node has been built to leverage a single-threaded event loop using asynchronous callbacks. The Node team blogged in 2011 about how “Node.js promotes an asynchronous coding style from the ground up.” In Ryan Dahl’s talk announcing Node.js in 2009, he talks about the performance benefits of doubling down on asynchronous JavaScript.
The asynchronous-first style is part of the reason Node gained popularity over other attempts at server-side JavaScript implementations such as Netscape’s application servers or Narwhal. However, being forced to write asynchronous JavaScript might cause friction if you aren’t ready for it.
Setting up an example
Let’s say we’re writing a quiz app. We’re going to allow users to build quizes out of multichoice questions to test their friends’ knowledge. You can find a more complete version of what we’ll build at this GitHub repo. You could also clone the entire front-end and back-end to see how it all fits together, or you can take a look at this CodeSandbox (run npm run start to fire it up) and get an idea of what we’re making from there.
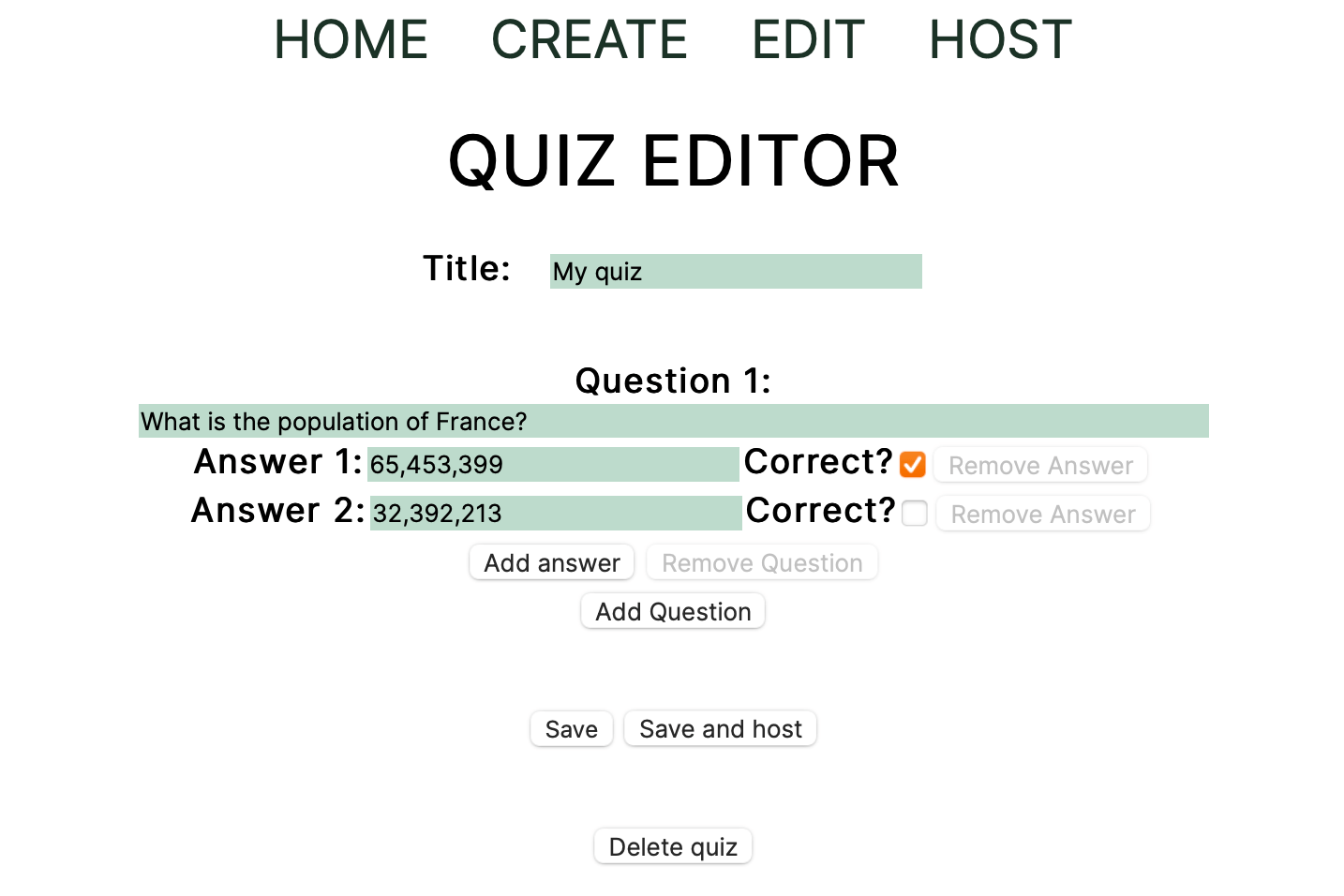
The quizzes in our app will consist of a bunch of questions, and each of these questions will have a number of answers to choose from, with only one answer being correct.
We can hold this data in an SQLite database. Our database will contain:
- A table for quizzes with two columns:
- an integer ID
- a text title
- A table for questions with three columns:
- an integer ID
- body text
- An integer reference matching the ID of the quiz each question belongs to
- A table for answers with four columns:
- an integer ID
- body text
- whether the answer is correct or not
- an integer reference matching the ID of the question each answer belongs to
SQLite doesn’t have a boolean data type, so we can hold whether an answer is correct in an integer where 0 is false and 1 is true.
First, we’ll need to initialize npm and install the sqlite3 npm package from the command line:
npm init -y
npm install sqlite3This will create a package.json file. Let’s edit it and add:
"type":"module"To the top-level JSON object. This will allow us to use modern ES6 module syntax. Now we can create a node script to set up our tables. Let’s call our script migrate.js.
// migrate.js import sqlite3 from "sqlite3"; let db = new sqlite3.Database("quiz.db"); db.serialize(function () { // Setting up our tables: db.run("CREATE TABLE quiz (quizid INTEGER PRIMARY KEY, title TEXT)"); db.run("CREATE TABLE question (questionid INTEGER PRIMARY KEY, body TEXT, questionquiz INTEGER, FOREIGN KEY(questionquiz) REFERENCES quiz(quizid))"); db.run("CREATE TABLE answer (answerid INTEGER PRIMARY KEY, body TEXT, iscorrect INTEGER, answerquestion INTEGER, FOREIGN KEY(answerquestion) REFERENCES question(questionid))"); // Create a quiz with an id of 0 and a title "my quiz" db.run("INSERT INTO quiz VALUES(0,"my quiz")"); // Create a question with an id of 0, a question body // and a link to the quiz using the id 0 db.run("INSERT INTO question VALUES(0,"What is the capital of France?", 0)"); // Create four answers with unique ids, answer bodies, an integer for whether // they're correct or not, and a link to the first question using the id 0 db.run("INSERT INTO answer VALUES(0,"Madrid",0, 0)"); db.run("INSERT INTO answer VALUES(1,"Paris",1, 0)"); db.run("INSERT INTO answer VALUES(2,"London",0, 0)"); db.run("INSERT INTO answer VALUES(3,"Amsterdam",0, 0)"); });
db.close();I’m not going to explain this code in detail, but it creates the tables we need to hold our data. It will also create a quiz, a question, and four answers, and store all of this in a file called quiz.db. After saving this file, we can run our script from the command line using this command:
node migrate.jsIf you like, you can open the database file using a tool like DB Browser for SQLite to double check that the data has been created.
Changing the way you write JavaScript
Let’s write some code to query the data we’ve created.
Create a new file and call it index.js .To access our database, we can import sqlite3, create a new sqlite3.Database, and pass the database file path as an argument. On this database object, we can call the get function, passing in an SQL string to select our quiz and a callback that will log the result:
// index.js
import sqlite3 from "sqlite3"; let db = new sqlite3.Database("quiz.db"); db.get(`SELECT * FROM quiz WHERE quizid = 0`, (err, row) => { if (err) { console.error(err.message); } console.log(row); db.close();
});Running this should print { quizid: 0, title: 'my quiz' } in the console.
How not to use callbacks
Now let’s wrap this code in a function where we can pass the ID in as an argument; we want to access any quiz by its ID. This function will return the database row object we get from db.
Here’s where we start running into trouble. We can’t simply return the object inside of the callback we pass to db and walk away. This won’t change what our outer function returns. Instead, you might think we can create a variable (let’s call it result) in the outer function and reassign this variable in the callback. Here is how we might attempt this:
// index.js
// Be warned! This code contains BUGS
import sqlite3 from "sqlite3"; function getQuiz(id) { let db = new sqlite3.Database("quiz.db"); let result; db.get(`SELECT * FROM quiz WHERE quizid = ?`, [id], (err, row) => { if (err) { return console.error(err.message); } db.close(); result = row; }); return result;
}
console.log(getQuiz(0));If you run this code, the console log will print out undefined! What happened?
We’ve run into a disconnect between how we expect JavaScript to run (top to bottom), and how asynchronous callbacks run. The getQuiz function in the above example runs like this:
- We declare the
resultvariable withlet result;. We haven’t assigned anything to this variable so its value isundefined. - We call the
db.get()function. We pass it an SQL string, the ID, and a callback. But our callback won’t run yet! Instead, the SQLite package starts a task in the background to read from thequiz.dbfile. Reading from the file system takes a relatively long time, so this API lets our user code move to the next line while Node.js reads from the disk in the background. - Our function returns
result. As our callback hasn’t run yet,resultstill holds a value ofundefined. - SQLite finishes reading from the file system and runs the callback we passed, closing the database and assigning the row to the
resultvariable. Assigning this variable makes no difference as the function has already returned its result.
Passing in callbacks
How do we fix this? Before 2015, the way to fix this would be to use callbacks. Instead of only passing the quiz ID to our function, we pass the quiz ID and a callback which will receive the row object as an argument.
Here’s how this looks:
// index.js
import sqlite3 from "sqlite3";
function getQuiz(id, callback) { let db = new sqlite3.Database("quiz.db"); db.get(`SELECT * FROM quiz WHERE quizid = ?`, [id], (err, row) => { if (err) { console.error(err.message); } else { callback(row); } db.close(); });
}
getQuiz(0,(quiz)=>{ console.log(quiz);
});That does it. It’s a subtle difference, and one that forces you to change the way your user code looks, but it means now our console.log runs after the query is complete.
Callback hell
But what if we need to do multiple consecutive asynchronous calls? For instance, what if we were trying to find out which quiz an answer belonged to, and we only had the ID of the answer.
First, I’m going to refactor getQuiz to a more general get function, so we can pass in the table and column to query, as well as the ID:
Unfortunately, we are unable to use the (more secure) SQL parameters for parameterizing the table name, so we’re going to switch to using a template string instead. In production code you would need to scrub this string to prevent SQL injection.
function get(params, callback) { // In production these strings should be scrubbed to prevent SQL injection const { table, column, value } = params; let db = new sqlite3.Database("quiz.db"); db.get(`SELECT * FROM ${table} WHERE ${column} = ${value}`, (err, row) => { callback(err, row); db.close(); });
}Another issue is that there might be an error reading from the database. Our user code will need to know whether each database query has had an error; otherwise it shouldn’t continue querying the data. We’ll use the Node.js convention of passing an error object as the first argument of our callback. Then we can check if there’s an error before moving forward.
Let’s take our answer with an id of 2 and check which quiz it belongs to. Here’s how we can do this with callbacks:
// index.js
import sqlite3 from "sqlite3"; function get(params, callback) { // In production these strings should be scrubbed to prevent SQL injection const { table, column, value } = params; let db = new sqlite3.Database("quiz.db"); db.get(`SELECT * FROM ${table} WHERE ${column} = ${value}`, (err, row) => { callback(err, row); db.close(); });
} get({ table: "answer", column: "answerid", value: 2 }, (err, answer) => { if (err) { console.log(err); } else { get( { table: "question", column: "questionid", value: answer.answerquestion }, (err, question) => { if (err) { console.log(err); } else { get( { table: "quiz", column: "quizid", value: question.questionquiz }, (err, quiz) => { if (err) { console.log(err); } else { // This is the quiz our answer belongs to console.log(quiz); } } ); } } ); }
});Woah, that’s a lot of nesting! Every time we get an answer back from the database, we have to add two layers of nesting — one to check for an error, and one for the next callback. As we chain more and more asynchronous calls our code gets deeper and deeper.
We could partially prevent this by using named functions instead of anonymous functions, which would keep the nesting lower, but make our code our code less concise. We’d also have to think of names for all of these intermediate functions. Thankfully, promises arrived in Node back in 2015 to help with chained asynchronous calls like this.
Promises
Wrapping asynchronous tasks with promises allows you to prevent a lot of the nesting in the previous example. Rather than having deeper and deeper nested callbacks, we can pass a callback to a Promise’s then function.
First, let’s change our get function so it wraps the database query with a Promise:
// index.js
import sqlite3 from "sqlite3";
function get(params) { // In production these strings should be scrubbed to prevent SQL injection const { table, column, value } = params; let db = new sqlite3.Database("quiz.db"); return new Promise(function (resolve, reject) { db.get(`SELECT * FROM ${table} WHERE ${column} = ${value}`, (err, row) => { if (err) { return reject(err); } db.close(); resolve(row); }); });
}Now our code to search for which quiz an answer is a part of can look like this:
get({ table: "answer", column: "answerid", value: 2 }) .then((answer) => { return get({ table: "question", column: "questionid", value: answer.answerquestion, }); }) .then((question) => { return get({ table: "quiz", column: "quizid", value: question.questionquiz, }); }) .then((quiz) => { console.log(quiz); }) .catch((error) => { console.log(error); }
);That’s a much nicer way to handle our asynchronous code. And we no longer have to individually handle errors for each call, but can use the catch function to handle any errors that happen in our chain of functions.
We still need to write a lot of callbacks to get this working. Thankfully, there’s a newer API to help! When Node 7.6.0 was released, it updated its JavaScript engine to V8 5.5 which includes the ability to write ES2017 async/await functions.
Async/Await
With async/await we can write our asynchronouse code almost the same way we write synchronous code. Sarah Drasner has a great post explaining async/await.
When you have a function that returns a Promise, you can use the await keyword before calling it, and it will prevent your code from moving to the next line until the Promise is resolved. As we’ve already refactored the get() function to return a promise, we only need to change our user-code:
async function printQuizFromAnswer() { const answer = await get({ table: "answer", column: "answerid", value: 2 }); const question = await get({ table: "question", column: "questionid", value: answer.answerquestion, }); const quiz = await get({ table: "quiz", column: "quizid", value: question.questionquiz, }); console.log(quiz);
} printQuizFromAnswer();This looks much more familiar to code that we’re used to reading. Just this year, Node released top-level await. This means we can make this example even more concise by removing the printQuizFromAnswer() function wrapping our get() function calls.
Now we have concise code that will sequentially perform each of these asynchronous tasks. We would also be able to simultaneously fire off other asynchronous functions (like reading from files, or responding to HTTP requests) while we’re waiting for this code to run. This is the benefit of all the asynchronous style.
As there are so many asynchronous tasks in Node, such as reading from the network or accessing a database or filesystem. It’s especially important to understand these concepts. It also has a bit of a learning curve.
Using SQL to its full potential
There’s an even better way! Instead of having to worry about these asynchronous calls to get each piece of data, we could use SQL to grab all the data we need in one big query. We can do this with an SQL JOIN query:
// index.js
import sqlite3 from "sqlite3"; function quizFromAnswer(answerid, callback) { let db = new sqlite3.Database("quiz.db"); db.get( `SELECT *,a.body AS answerbody, ques.body AS questionbody FROM answer a INNER JOIN question ques ON a.answerquestion=ques.questionid INNER JOIN quiz quiz ON ques.questionquiz = quiz.quizid WHERE a.answerid = ?;`, [answerid], (err, row) => { if (err) { console.log(err); } callback(err, row); db.close(); } );
}
quizFromAnswer(2, (e, r) => { console.log(r);
});This will return us all the data we need about our answer, question, and quiz in one big object. We’ve also renamed each body column for answers and questions to answerbody and questionbody to differentiate them. As you can see, dropping more logic into the database layer can simplify your JavaScript (as well as possibly improve performance).
If you’re using a relational database like SQLite, then you have a whole other language to learn, with a whole lot of different features that could save time and effort and increase performance. This adds more to the pile of things to learn for writing Node.
Node APIs and conventions
There are a lot of new node APIs to learn when switching from browser code to Node.js.
Any database connections and/or reads of the filesystem use APIs that we don’t have in the browser (yet). We also have new APIs to set up HTTP servers. We can make checks on the operating system using the OS module, and we can encrypt data with the Crypto module. Also, to make an HTTP request from node (something we do in the browser all the time), we don’t have a fetch or XMLHttpRequest function. Instead, we need to import the https module. However, a recent pull request in the node.js repository shows that fetch in node appears to be on the way! There are still many mismatches between browser and Node APIs. This is one of the problems that Deno has set out to solve.
We also need to know about Node conventions, including the package.json file. Most front-end developers will be pretty familiar with this if they’ve used build tools. If you’re looking to publish a library, the part you might not be used to is the main property in the package.json file. This property contains a path that will point to the entry-point of the library.
There are also conventions like error-first callbacks: where a Node API will take a callback which takes an error as the first argument and the result as the second argument. You could see this earlier in our database code and below using the readFile function.
import fs from 'fs'; fs.readFile('myfile.txt', 'utf8' , (err, data) => { if (err) { console.error(err) return } console.log(data)
})Different types of modules
Earlier on, I casually instructed you to throw "type":"module" in your package.json file to get the code samples working. When Node was created in 2009, the creators needed a module system, but none existed in the JavaScript specification. They came up with Common.js modules to solve this problem. In 2015, a module spec was introduced to JavaScript, causing Node.js to have a module system that was different from native JavaScript modules. After a herculean effort from the Node team we are now able to use these native JavaScript modules in Node.
Unfortunately, this means a lot of blog posts and resources will be written using the older module system. It also means that many npm packages won’t use native JavaScript modules, and sometimes there will be libraries that use native JavaScript modules in incompatible ways!
Other concerns
There are a few other concerns we need to think about when writing Node. If you’re running a Node server and there is a fatal exception, the server will terminate and will stop responding to any requests. This means if you make a mistake that’s bad enough on a Node server, your app is broken for everyone. This is different from client-side JavaScript where an edge-case that causes a fatal bug is experienced by one user at a time, and that user has the option of refreshing the page.
Security is something we should already be worried about in the front end with cross-site scripting and cross-site request forgery. But a back-end server has a wider surface area for attacks with vulnerabilities including brute force attacks and SQL injection. If you’re storing and accessing people’s information with Node you’ve got a big responsibility to keep their data safe.
Conclusion
Node is a great way to use your JavaScript skills to build servers and command line tools. JavaScript is a user-friendly language we’re used to writing. And Node’s async-first nature means you can smash through concurrent tasks quickly. But there are a lot of new things to learn when getting started. Here are the resources I wish I saw before jumping in:
And if you are planning to hold data in an SQL database, read up on SQL Basics.